

No free lunch
The promised land of the modern data stack has an ugly underside

Note: I hope that whatever critiques I share in this blog about Fivetran’s product only amplify how grateful I am to the Fivetran sales team for getting me unblocked and ultimately successful
Our most recent pivot, Perpetual, is software for customer success teams. Our aim is to help Customer Success Managers (CSMs) proactively identify customers who may be at risk for churn, understand why those customers are at risk, and automatically take action to reduce churn risk.
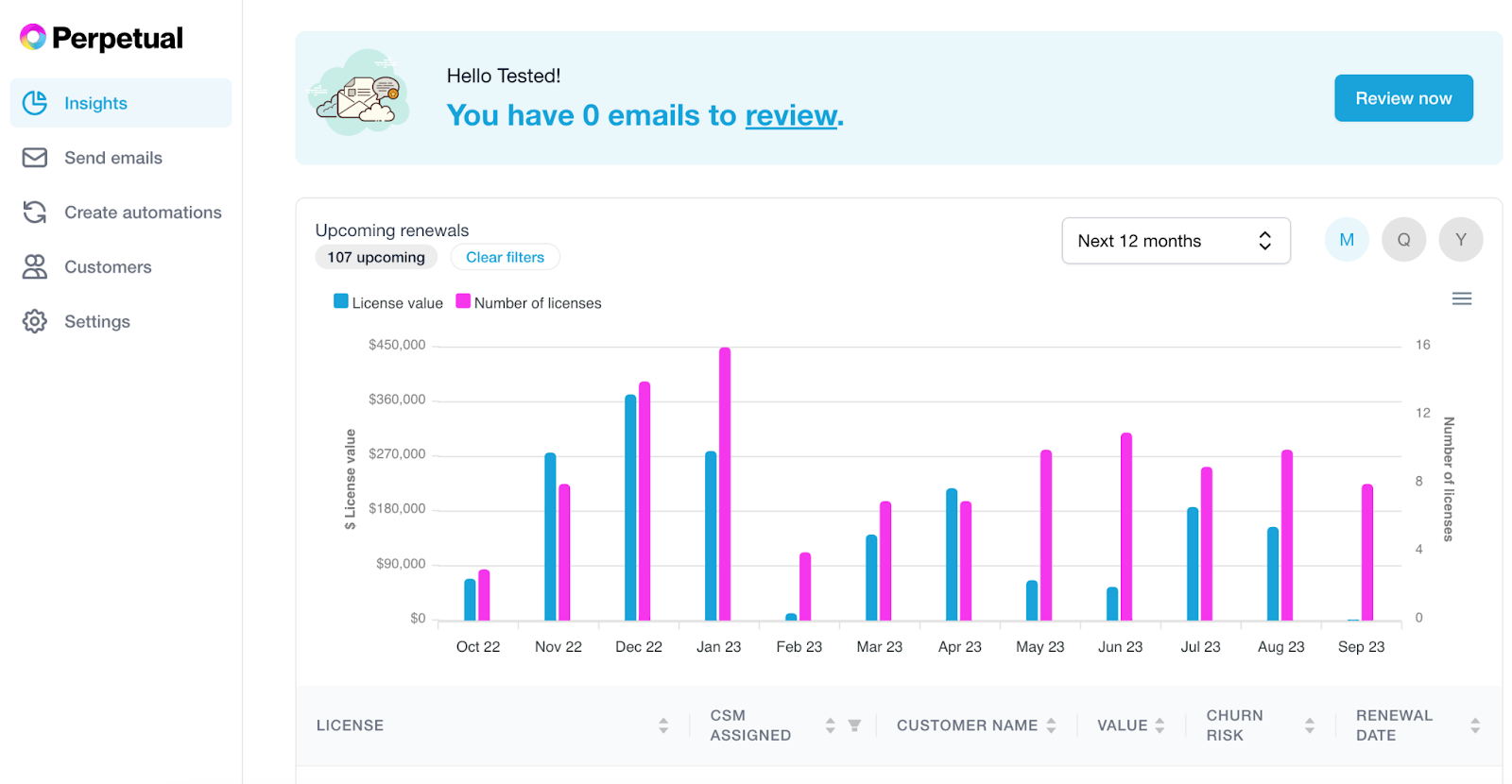
Perpetual’s homepage displays a bird’s-eye view of upcoming renewals
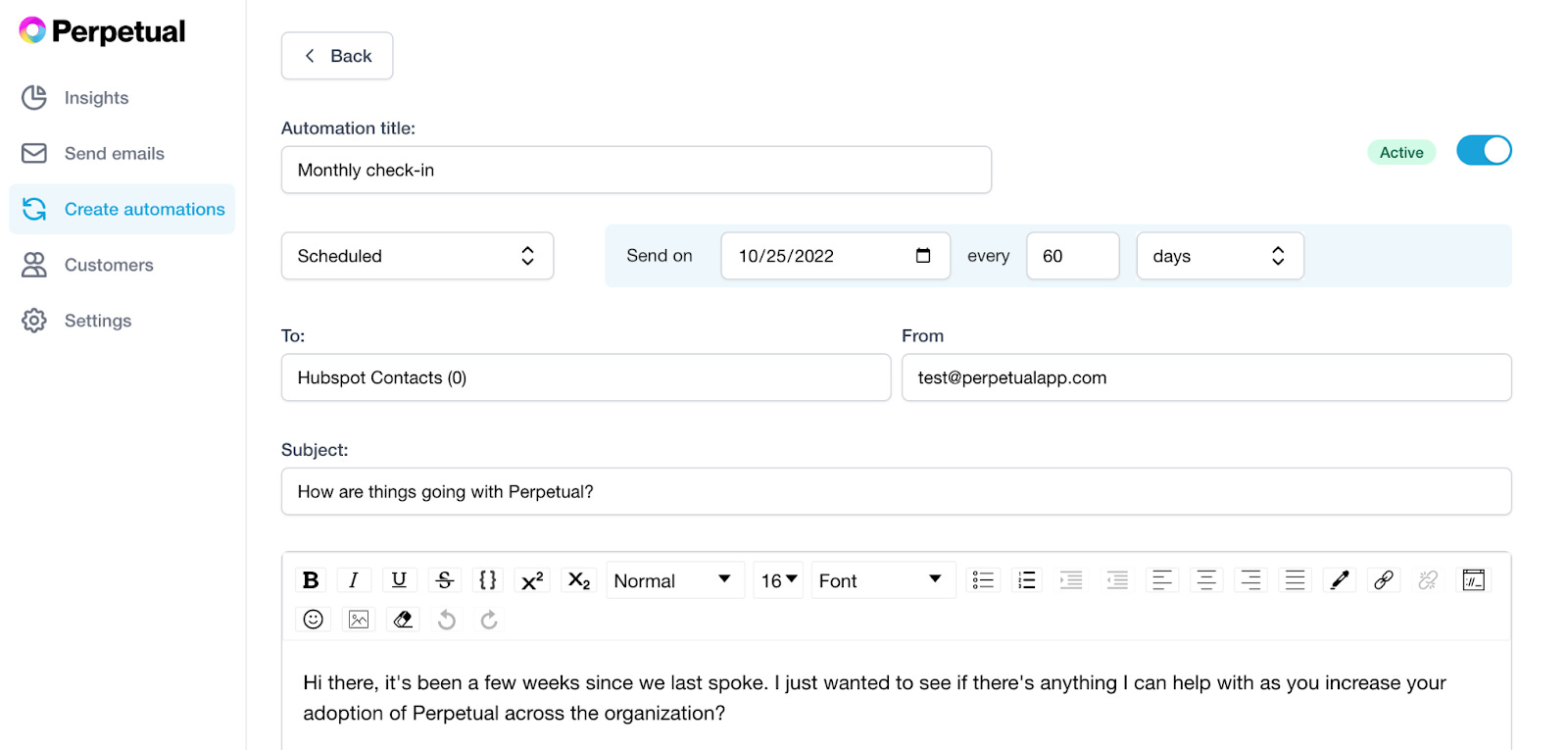
Perpetual’s email automations flow lets CSMs check in with their customers in response to key events
One thing you’ll notice about Perpetual is that in order to work it needs data: customer names, emails, license terms, license values, customer usage. And until Perpetual takes over the world, we need to import that data from somewhere else.
The first, and most important data source for Perpetual is our customers’ Client Relationship Management (CRM) software. While CRMs are primarily used by sales teams to track new business, customer success teams without dedicated software of their own often default to using the CRM to track existing business.
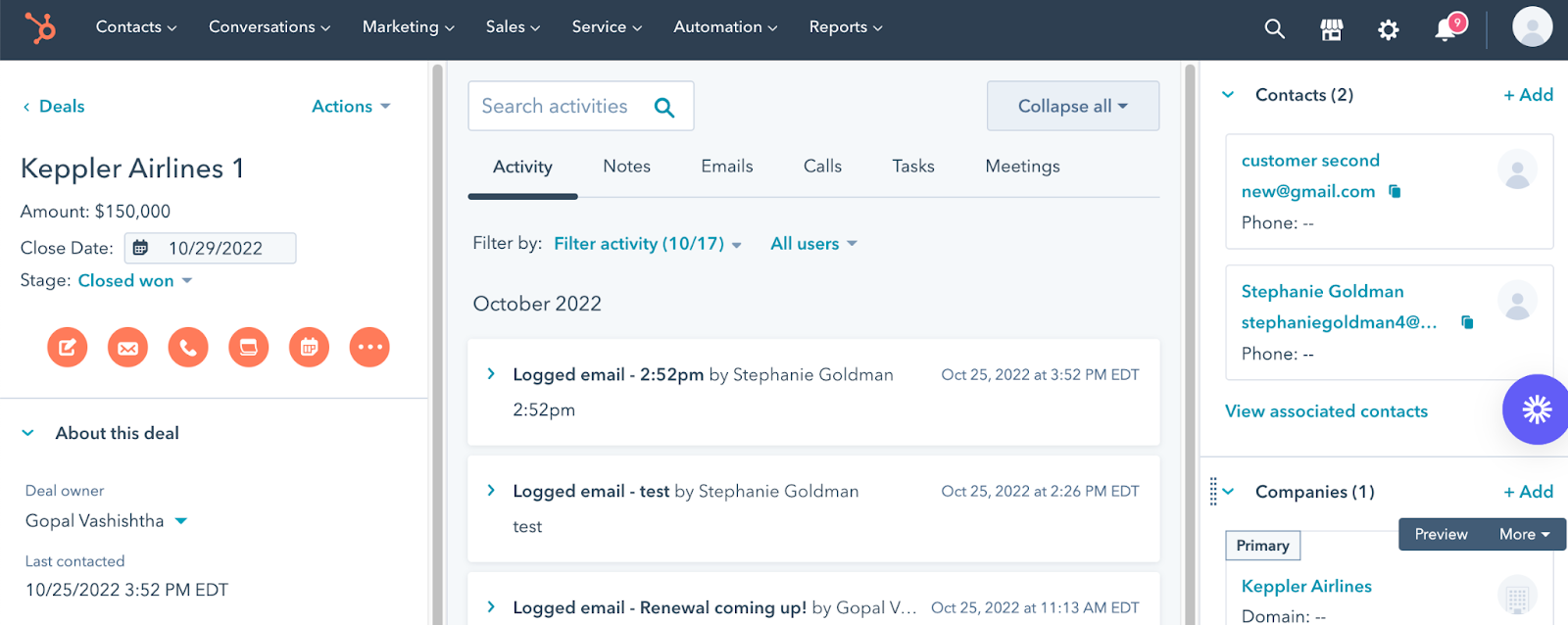
An example of how a customer success team might track an existing contract inside of Hubspot, a popular CRM
Because getting data out of a CRM and into Perpetual is the first step in customers’ journey with Perpetual, building data pipelines is where I’ve spent my engineering effort over the past month or so. I started by rolling my own data pipeline in Python but then decided to use an off-the-shelf tool called Fivetran. This blog post explains the tradeoffs we encountered as a result of that decision.
Problem statement
Hubspot exposes its data via the following REST APIs:
/owners - returns information about the users of Hubspot
/companies - returns information about companies tracked in Hubspot
/contacts - returns information about “contacts,” usually employees of companies tracked in Hubspot
/deals - tracks an opportunity to generate revenue. For existing customers, CSMs will often create deals to track the next time a company renews. i.e. I sign a 1-year license with Slack ending in 2023. Slack’s CSM will create a “deal” with a 2024 end date to track my upcoming renewal.
/associations - tracks mappings between the preceding 3 types of objects. i.e. contacts can be assigned to one or more companies, deals can be assigned to companies, and contacts can be assigned to deals.
Our backend is written in Supabase, so we wanted to store the data from Hubspot’s APIs in one of four tables in our PostgreSQL database:
customers - equivalent to “owners” in Hubspot
external_companies - equivalent to “companies” in Hubspot
external_customers - equivalent to “contacts” in Hubspot
licenses - equivalent to “deals” in Hubspot
Many of the tables above contain foreign keys that I populated using the /associations API.
v1 Solution
My first solution for the problem of importing data from Hubspot was entirely homegrown. Using Flask, I wrote code that would:
Initiate an OAuth flow to store a user’s Hubspot credentials in Supabase
Store a user-provided mapping between Hubspot fields and Perpetual fields
Store user-provided filtering logic
Query Hubspot’s APIs to read data from Hubspot into memory
Execute a bulk upsert through the SQLAlchemy ORM to store those values in our database
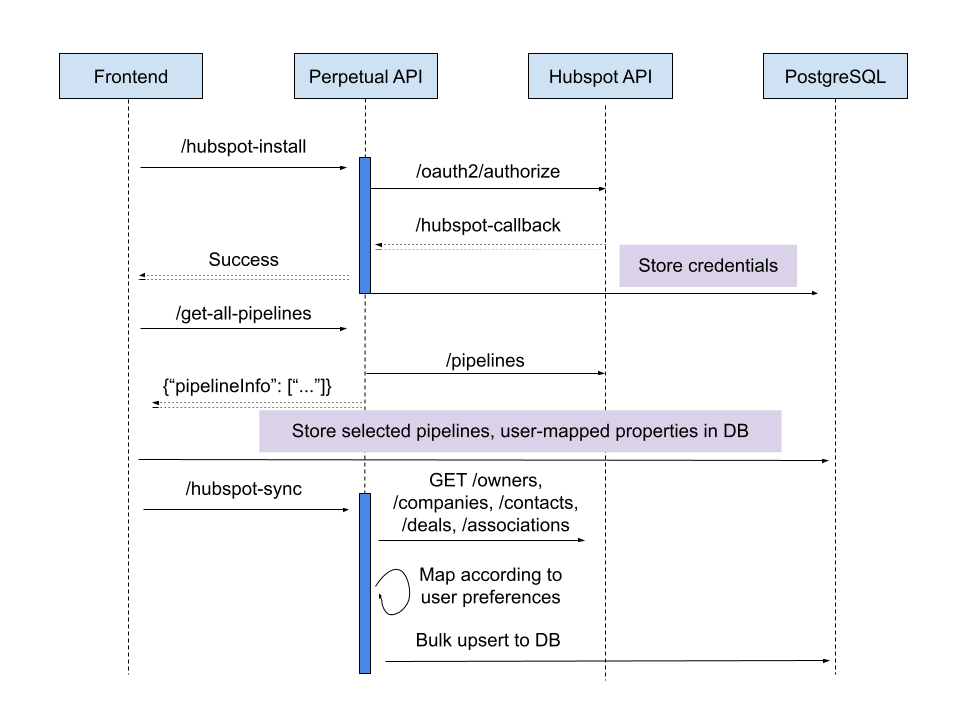
Python-based data pipeline
Pros
Some of the benefits of this solution were:
Low space usage. By letting users import only the pipeline they cared about, and then using the associations API to get the associated companies and contacts, I ensured to only import the data we cared about and was able to keep our data footprint in the hundreds of MBs
Easy to onboard. Any engineer who knows Python will be able to immediately understand how our data pipeline worked without having to learn a new toolchain
Cons
Some of the issues we ran into were:
Slow performance with naive imports. While the pipeline performed fine in our test account with a dozen records, when I load tested with 1000s of records or more, the query time spiked. I was able to speed things up by letting users specify filters prior to import and then importing only relevant deals. I also switched to using bulk export/search APIs instead of reading records one at a time. But my approach for optimizing import was very specific to Hubspot
Scheduling not built-in. fetching new records automatically would have required setting up a cron job in GCP
Alerting not built-in. I would have had to look for 500 errors through an APM tool like Sentry in order to know if our imports had failed
Difficult to add new schemas. Soon after I launched the initial import functionality, we decided we wanted to import new emails. I would have had to learn the APIs for requesting emails in order to bring in this new data type.
v2 Solution
Especially because our roadmap called for integrating with other CRMs and various other data sources, we wanted to find a more scalable way to integrate data. So we looked to Fivetran, a startup behemoth recently valued at $5.6 billion. While we also evaluated airbyte, one of Fivetran’s open source competitors, only Fivetran seemed to have API support in general availability, as part of its Powered By Fivetran offering.
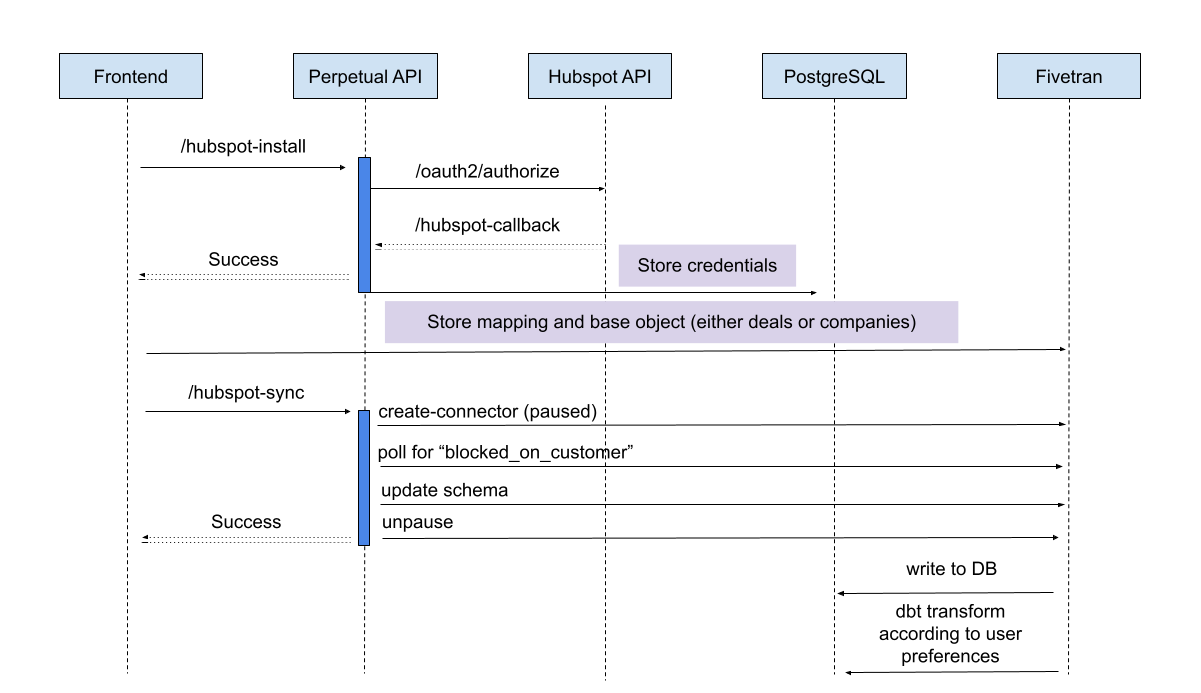
Data pipeline with Fivetran
My new architecture looked like:
Initiate an OAuth flow to store a user’s Hubspot credentials in Supabase
Make a Fivetran API call to create a paused connector from the user’s Hubspot account to our Supabase instance
Update the Fivetran schema to exclude tables that we didn’t want to import
Manually unpause the Fivetran pipeline
Every hour, run a dbt pipeline that transforms data from the Fivetran schema and upserts it into tables in our database’s public schema
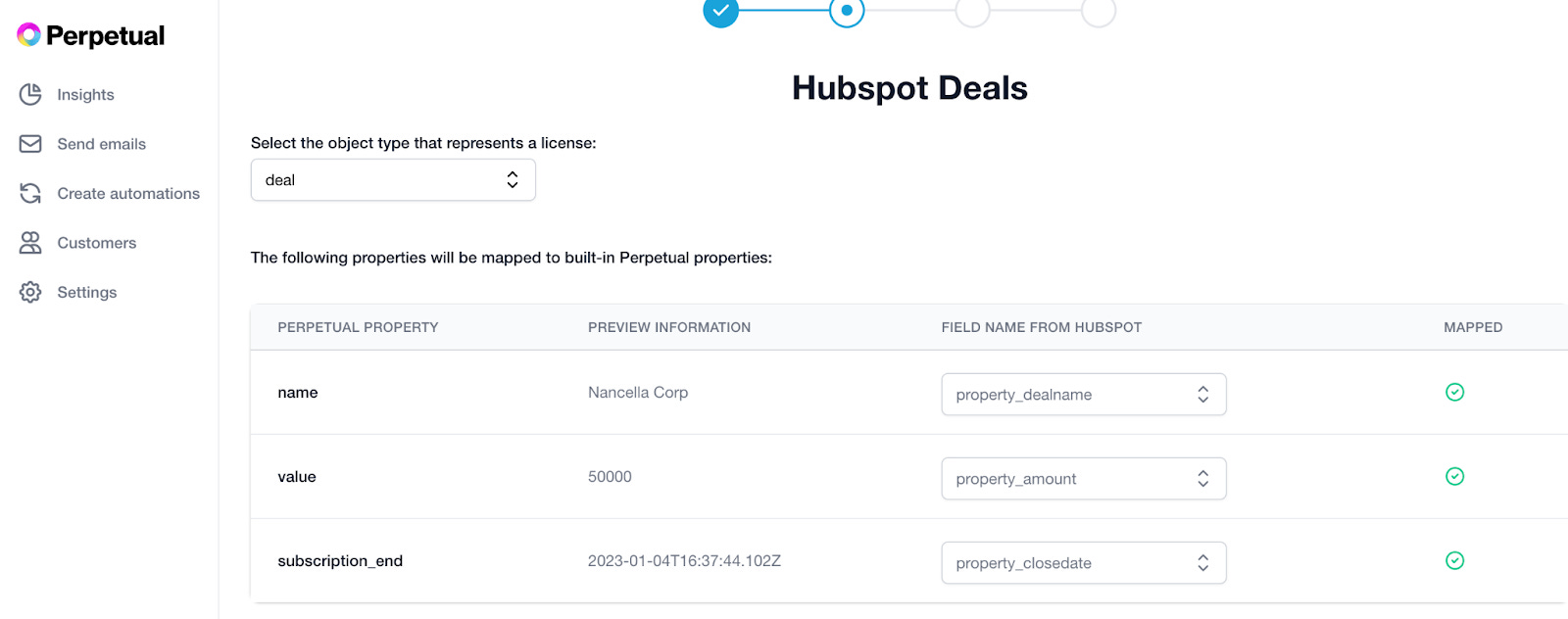
Creating a mapping from Hubspot fields to Perpetual fields
Pros
Syncs now run on a schedule
Fivetran automatically retries when Hubspot rate-limiting kicks in (on our plan it’s set to 100 API calls every 10 seconds)
I don’t have to learn Hubspot schemas
We’re automatically alerted when pipelines and transformations fail
I don’t have to figure out how to host our dbt jobs
I could delete 500 lines of Python
Cost - I went back and forth about whether to list this as a “con.” Fivetran’s model is usage-based, which is scary, but even at that astronomical volume of 2 million active rows per month, we’d be paying Fivetran (and a part-time analytics engineer) less than we would have to pay a backend engineer to maintain a forest of data pipeline logic
Cons
While Fivetran lets you avoid importing certain tables, there’s no way to filter out certain rows within a table. This limitation works out great for Fivetran, which charges by monthly active rows, but it means we’re paying to move a bunch of sales-related data that we don’t care about
Most annoyingly, Fivetran doesn’t let us specify a company ID in the “create connector” call. That means the only way to know which company we’re importing data for is to store each company’s data in a separate schema, and then put the company’s ID in the name of the schema. So we end up with ugly dbt logic like this:
{%- macro get_company_id(relation) -%}
split_part(
replace('{{ relation }}', '_hyp_', '-'),
'_', 2)::uuid
{%- endmacro -%}to figure out which company a record belongs to
Fivetran doesn’t have bi-directional sync, meaning we’re still stuck maintaining code to do things like logging emails sent from within Perpetual in Hubspot. In fairness, maybe we need something like Hightouch embedded for this piece.
While Fivetran populates DEAL_COMPANY and DEAL_CONTACT tables, it doesn’t populate a COMPANY_CONTACT table, meaning we have only a lossy mapping about which companies contacts belong to
Fivetran’s “fully integrated” dbt transform requires you to specify the schema of the connector in a source.yml file, but that’s not easy/convenient to do if your connectors change dynamically
Fivetran’s pre-built dbt transforms didn’t do anything we needed out of the box (obviously)
Fivetran’s API ergonomics are clunky: first create, then wait for schema to populate, then deactivate columns. I found I would have to set up a Celery worker just to poll their API to know when a sync is ready to begin
OK, so this one isn’t a problem with Fivetran, but dbt’s default incremental modeling for Postgres is to delete and then insert rows, which throws errors if the rows you are deleting are referenced as foreign keys by another table. So I had to actually overwrite the macro which felt like I was diving way too deep in abstraction layers.
No free lunch here
So would I recommend Powered By Fivetran to someone looking to embed their user’s data into their product without having to learn a bunch of random APIs?
Definitely, with the following caveat:
You are going to have to learn someone’s schema.
While Fivetran is great at pulling in JSON data from rate-limited REST APIs and munging that data into something that can be inserted into a relational database, ultimately Fivetran is going to produce data with a different schema for every upstream connector. That means when it’s time to add Salesforce, I’m going to need different dbt logic. From a technical debt perspective, now instead of maintaining 500 lines of Python, I’m maintaining 200 lines of dbt.
We are still going to have to build our own way for users to tell us what filters they’d like to apply to the data in Perpetual. That means writing code that accepts user-provided JSON, parses it, and then dynamically constructs a SQL query that executes the expected query.
If that tradeoff seems worthwhile, give Fivetran a shot!